Here is what usually happens when a team gets excited about agentic AI.
Someone reads a paper, or watches a demo, or sits through a conference talk where an LLM-powered system autonomously browses the web, writes code, calls APIs, evaluates its own output, and iterates until it solves a problem that would have taken a human engineer three hours. The demo is impressive. The system is genuinely impressive. And so the team comes back with a plan: we’re going to build an agent that handles our query understanding pipeline. Or our catalog enrichment. Or our entire ranking stack.
Two months later, one of two things has happened: either the project is quietly shelved because it turned out to be harder than expected, or the team is running something in production that looks almost nothing like the demo — and calling it an agent because that’s the word they started with.
I’ve seen both outcomes. Neither is anyone’s fault. The word “agentic” is doing a lot of work it wasn’t built for.
What the word actually means
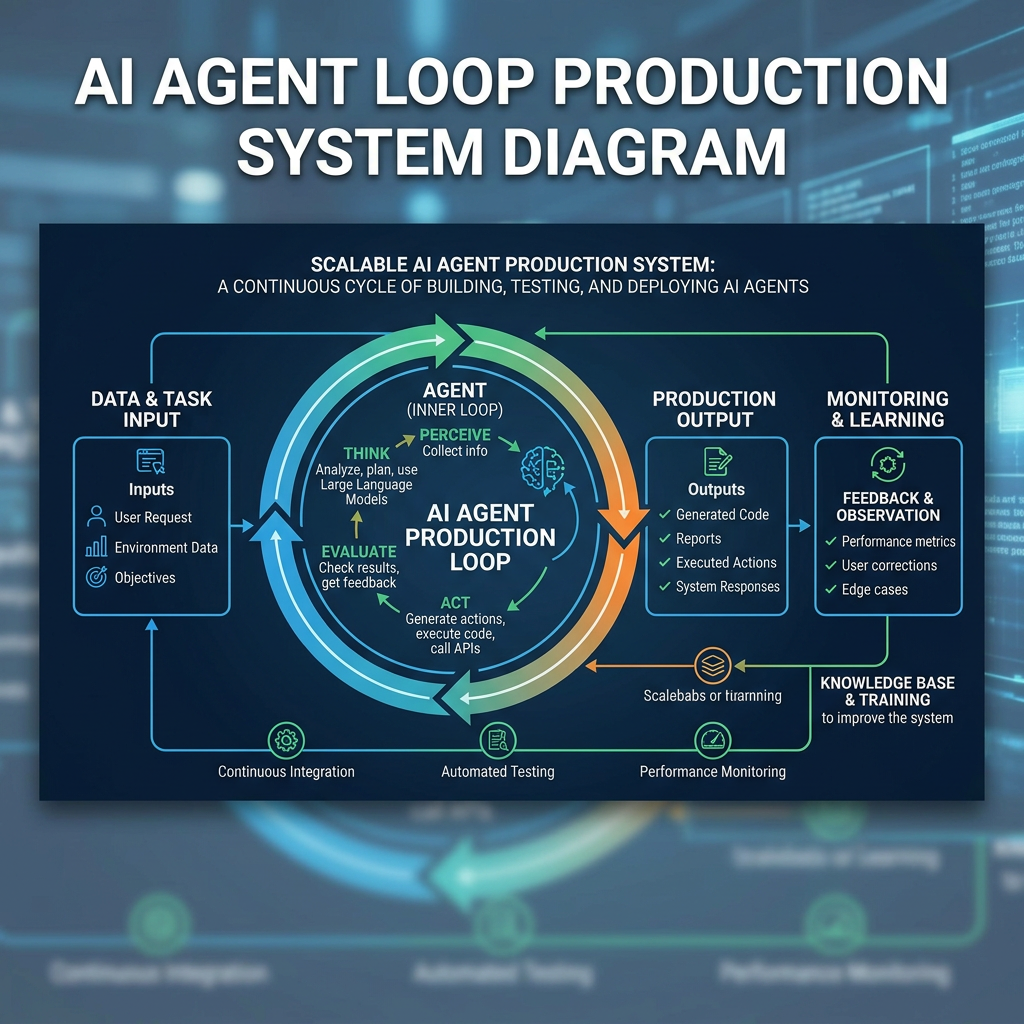
An agent, in the technical sense, is a system that:
- Observes some state of the world
- Chooses an action based on that observation (usually via an LLM)
- Executes the action (calls a tool, writes to a store, queries an API)
- Observes the new state
- Repeats until a goal condition is met or a budget is exhausted
That’s it. The loop is the thing. What makes it “agentic” is not the model, not the reasoning quality, not the number of tools available — it’s the presence of a closed loop where the system acts, sees the result, and decides what to do next.
This sounds simple. It is not.
What the loop looks like in practice
In a search or recommendation system, a concrete agentic pattern might look like this:
Query enrichment agent. A user types “running shoes for flat feet.” Your retrieval system returns mediocre results — you can tell because a re-ranking model gives them low scores. The agent observes this, calls a query expansion tool (“add terms: orthopedic, arch support, stability”), re-retrieves, compares result sets, and decides whether to serve the expanded set or fall back to the original.
That’s a real loop. It runs in a time budget. It calls tools. It makes decisions.
But notice what it is not: it is not autonomous in any meaningful sense. Every action is bounded. The tools are defined, tested, and deployed by engineers. The state the agent observes is structured and constrained. The goal condition is explicit. The agent is not browsing the web or improvising.
The useful mental model: an agent is a state machine where transitions are decided by an LLM instead of explicit rules. When you think of it that way, the design problems become clearer. State machines have states, transitions, terminal conditions, and error handling. So do agents. The LLM just makes the transition function more flexible — and more unpredictable.
The seams are the hard part
If I had to pick the one thing that production agentic systems taught me that the demos don’t, it’s this: the hard part is not the model. It’s the seams.
The seams are:
- Tool definitions. If a tool’s description is ambiguous, the LLM will call it in ways you didn’t intend. This is not a model problem. It’s a specification problem, and it’s yours to fix.
- State representation. What does the agent observe at each step? If the observation is incomplete, the agent will make bad decisions confidently. More confidence is not more accuracy.
- Failure handling. What happens when a tool call fails? When the LLM returns malformed output? When the loop doesn’t converge in three steps? Most demos handle none of this. Production systems handle all of it, because all of it happens.
- Knowing when not to call the model. This is the one people forget. For a significant fraction of inputs, the right move is to skip the agent entirely and route to a fast, deterministic system. An agent that runs on every query is expensive, slow, and often unnecessary. A good agentic system is mostly not running the LLM.
I’ve seen teams spend months tuning the LLM and a day on the scaffolding. The ratio should be closer to the reverse.
What “production” actually demands
A production system needs to answer some questions that demos don’t ask:
- Latency. An agentic loop that takes 800ms is unusable in a synchronous search ranking path. Either the loop is fast, or it runs asynchronously (enrichment, not retrieval). Or it doesn’t run.
- Observability. When the system serves a bad result, you need to know which step in the loop caused it. This requires logging at every transition, not just at the output. An agent that’s a black box is a liability.
- Degradation path. If the LLM is unavailable, or slow, or hallucinating, what does the system do? Fall back to the deterministic baseline? Serve cached output? Fail open or closed? The answer needs to be in the design from day one, not bolted on after the first production incident.
- Eval. This one is underrated. How do you know the agent is doing better than the non-agent baseline? “The outputs look good to me” is not an eval. You need a labeled set, a metric, and a comparison. Without this, you’re shipping vibes.
What’s worth building, and what isn’t
Agents are a good fit when:
- The task genuinely requires multiple steps of observation-action-observation
- The space of inputs is diverse enough that explicit rules can’t cover it
- You have latency budget to run a loop (async tasks, batch enrichment, offline pipelines)
- You can observe the outcome well enough to evaluate whether it worked
They’re a poor fit when:
- A single model call would do — you don’t need a loop if you don’t need feedback
- Latency is tight and there’s no async path
- You can’t observe the result (can’t eval = can’t improve = can’t trust)
- The “agentic” behavior could be a lookup table or a simple rule
The most common mistake I’ve seen is reaching for an agent when a well-prompted single-turn model call would have done the job at a tenth of the cost and latency. The second most common mistake is building an agentic loop without building the eval harness alongside it.
The honest summary
“Agentic” is not a quality of the model. It’s a property of the system architecture — specifically, the presence of a loop that observes, acts, and decides.
Building that loop correctly is mostly a software engineering problem, not an AI problem. It requires good tool design, explicit state, real failure handling, and relentless evaluation. The LLM is the decision function inside the loop, not the loop itself.
Once you see it that way, the question stops being “should we build an agent?” and becomes “do we need a loop here, and can we afford it?” That’s a much better question.
Most of the time, the answer is: not yet. But when it is yes, getting the scaffolding right is what separates a system that ships from a demo that doesn’t.

Leave a comment